
编订|Panda
联想这么一个场景:你正盯着屏幕,看着你的自主AI智能体(比如OpenClaw)放荡地运作。

它正在自主审查一个包含数十万行代码的史诗级开源神情,穿梭于无数的文献、API文档和调试日记之间。它弘扬得像一个不知疲顿的超等要领员,但在这「无所不行」的表象之下,藏匿着一个随时可能引爆的硬件梦魇——跟着高下文变得越来越长,大模子的「使命驰念」正在暴涨,像一个无底洞一样,冷凌弃地吞吃着漂后的GPU显存池!
这个令整个企业级AI成就者望风而遁的显存杀手,等于KVCache。
但目下,惩办决策来了,来自麻省理工学院(MIT)的盘考团队(AdamZweiger、XinghongFu等东说念主)。他们成就出了一种名为「把稳力匹配」(AttentionMatching)的全新潜在空间(LatentSpace)压缩技能。

论文标题:FastKVCompactionviaAttentionMatching
代码地址:https://github.com/adamzweiger/compaction
其有时在短短几秒钟内,将大型说话模子的高下文内存放荡压缩高达50倍,且险些莫得任何精度失掉!
这意味着原来需要一整个这个词H100GPU阵列才能勉强守旧的超长对话或巨型文档分析任务,目下可能只需要单张显卡就能松驰跑满并发。一场对于AI基础设施的后果改革,似乎已悄然打响。
漂后的使命驰念
大模子的阿喀琉斯之踵
要领会这项技能有何等逆天,咱们必须先直视大模子的软肋。
LLM是自追思的,它们生成回当令是逐token往外吐的。为了幸免在估计每一个新词时,皆要把长达几万字的聊天记载重新到尾再行诡计一遍,模子必须将之前处理过的每一个token的「数学灵魂」缓存起来——这些被提真金不怕火出来的多维向量,等于「键(Key)」和「值(Value)」对,即KVCache。
跟着高下文的拉伸,这层使命驰念会不可逆转地延伸。
在当代企业级期骗中,比如分析成百上千页的法律条约、保管长达数月的私东说念主AI伴侣驰念,或者运行OpenClaw这么的自治编码智能体,单单一个用户的央求,其KVCache就能须臾飙升到数十GB。
正如论文第一作家AdamZweiger所言:「在超长高下文处事中,KVCache是最大的物理瓶颈。它不仅死死锁住了并发量,将就你减轻批处理界限,致使逼着系统进行极其影响性能的无为卸载。」
靠近这个吞金兽,盘考者们曾尝试过很多决策:
Token丢弃与消逝(如H2O,SnapKV,PyramidKV等):这些法子试图踢掉那些模子认为「不进攻」的token。在轻度压缩时还能勉强,但一朝将压缩率拉高(比如试图压缩10倍以上),模子的才气就会遭受断崖式下降。
文本摘录:这是目下工业界最无奈的标配。当内存见底时,系统暂停,让模子我方写一段高下文总结,然后清空原有驰念。这种法子相配「有损」,会把极其重要的轻微细节(比如医疗记载里的一个荒僻方针)绝对抹除。
潜空间压缩(如Cartridges):这是近期的前沿探索,确认了高比例压缩不仅可行,而且还能保握高精度。但它的代价极其奋斗:它需要通过极其冉冉的端到端梯度下降来锻真金不怕火这些压缩后的驰念。为了压缩一段高下文,哪怕动用漂后的GPU,也需要耗尽数小时!这在条目「秒回」的及时企业期骗中,简直是离奇乖癖。
咱们需要一种既有Cartridges的精度,又有传统法子速率的终极魔法。而MIT的「把稳力匹配」,恰是为此而生。
窒碍常理的数学魔法
「把稳力匹配」的底层逻辑
MIT的盘考东说念主员莫得死磕冉冉的机器学习锻真金不怕火,而是想出了一个绝妙的数学捷径。他们退后一步,问了一个极其骨子的问题:当咱们压缩驰念时,模子究竟在乎什么?
谜底是:模子根蒂不在乎你存了几许个Key和Value,它只在乎当它抛出一个查询(Query,即q)时,滚球app中国官网下载入口这堆驰念能给它复返什么放纵!
为了完整糊弄AI,让它合计「压缩后的驰念和原来高大的驰念一模一样」,压缩后的键值对(C_k,C_v)必须严格匹配原始驰念的两个中枢数学属性:
把稳力输出(AttentionOutput):这是AI提真金不怕火到的现实信息向量。
把稳力质料(AttentionMass):这是极其重要的小数。在拼接新token或旧驰念时,一段驰念的话语权取决于它的「质料」。
若是你班师把1000个token压缩成20个,那么这20个token的「总质料」完全拼不外原来的1000个,这会导致模子在后续推理时,相配看不起这部分被压缩的驰念。为了破解这个死局,盘考团队引入了一个轻微但号称神来之笔的变量:每token标量偏差β。
这个β偏差就像是一个「杠杆权重」,它在把稳力诡计的指数层面上对保留住来的Key进行乘法重加权,让戋戋1个被保留的Key,有时爆发出代表50个被移除Key的巨大「质料」!
若是用严谨的数学说话(如论文中的公式1和2)来抒发,他们要优化的方向等于找到(C_k,β,C_v),使得对于整个关系的查询q:
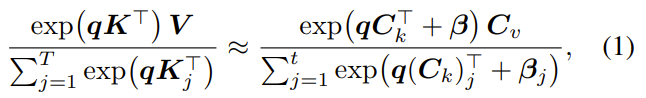
而且匹配总质料:
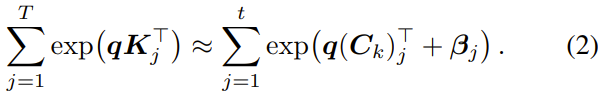
更惊东说念主的是,由于这种精妙的框架构建,这个看似复杂的非线性优化问题,果然自但是然地解体了!盘考东说念主员完全抛弃了吃算力的反向传播和梯度优化。
最初,锁定C_k后,质料匹配问题退化成了一个非负最小二乘法(NNLS)问题,须臾就能诡计出偏差β。
随后,把稳力输出匹配问题班师造成了一个程序的泛泛最小二乘法(OLS)问题,通过简便的代数矩阵运算,一忽儿就能求出压缩后的值C_v!
这简直是降维打击。原来需要数小时的锻真金不怕火,被线性代数优化到了以「秒」为单元。
来自VentureBeat,由AI生成
预判你的预判
奈何提真金不怕火「参测验询」与挑选「金钥匙」?
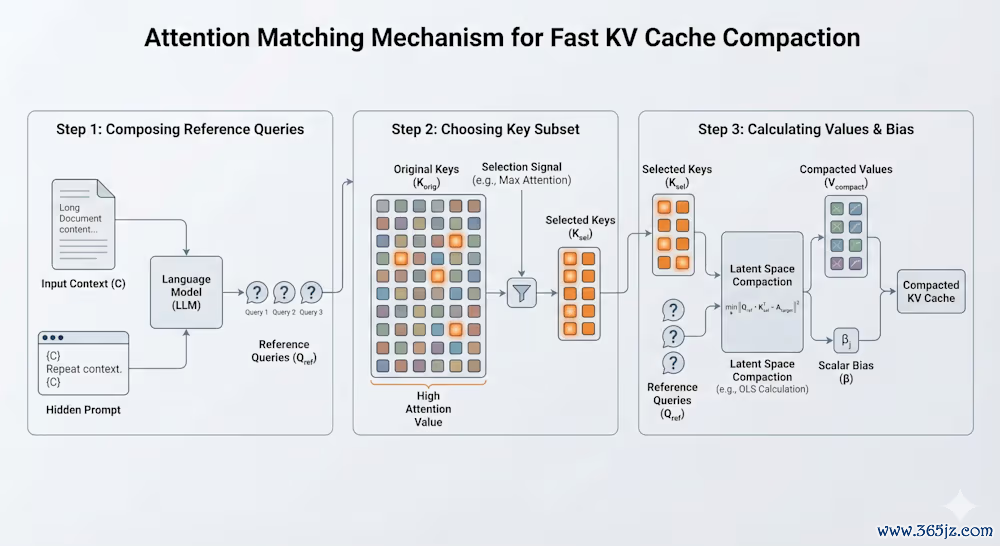
有了数学火器,正规投注平台官网接下来的工程落地不异惊艳。为了让压缩算法知说念该保留什么,系统需要一批「参测验询」(Q_ref),看成模子异日可能提议的问题的「替身」。
盘考团队遐想了极其机灵的「预演」机制:
重叠预填充:偷偷在文档末尾加一句保密领导:「重叠前边的高下文」,然后拿获模子在试图复述时产生的里面Query向量。
自我学习:让模子对文档进行快速的合成任务,比如「提真金不怕火整个中枢事实」或「把日历结构化为JSON」,从而嗅探出模子在深度推理时会生成什么样的Query。
手里攥着这些极具代表性的Query探针,系统运行从原始的茫茫Key海中挑选「金钥匙」(C_k)。论文中提供了两种法子:
最高把稳力法(HighestAttentionKeys):这是一种闪电般的启发式法子,班师挑出在参测验询中被讲理度最高的Keys。速率极快,性价比超高。
正交匹配跟踪(OrthogonalMatchingPursuit,OMP):这是一种愈加极客和贪心的算法。它像搭积木一样,每一步皆精挑细选一个最能填补「质料差错」残差的Key,然后用NNLS再行校准权重。固然稍稍耗时(还是只是几分钟级别),但能将压实质料推向巅峰(AM-OMP)。

并非整个「把稳力」生来对等
非均匀压缩战略
这还不是重心,在深远探索模子架构时,他们发现了一个意旨的景色:在多头把稳力机制中,并非整个的「头」皆是使命狂。
有些Head相配贪心,需要高大的KV容量才能保握性能(比如细致长程依赖的Head);而另一些Head则极其佛系,哪怕你把它的驰念砍掉90%,它还是能完整运转(比如只讲理局部词法结构的Head)。
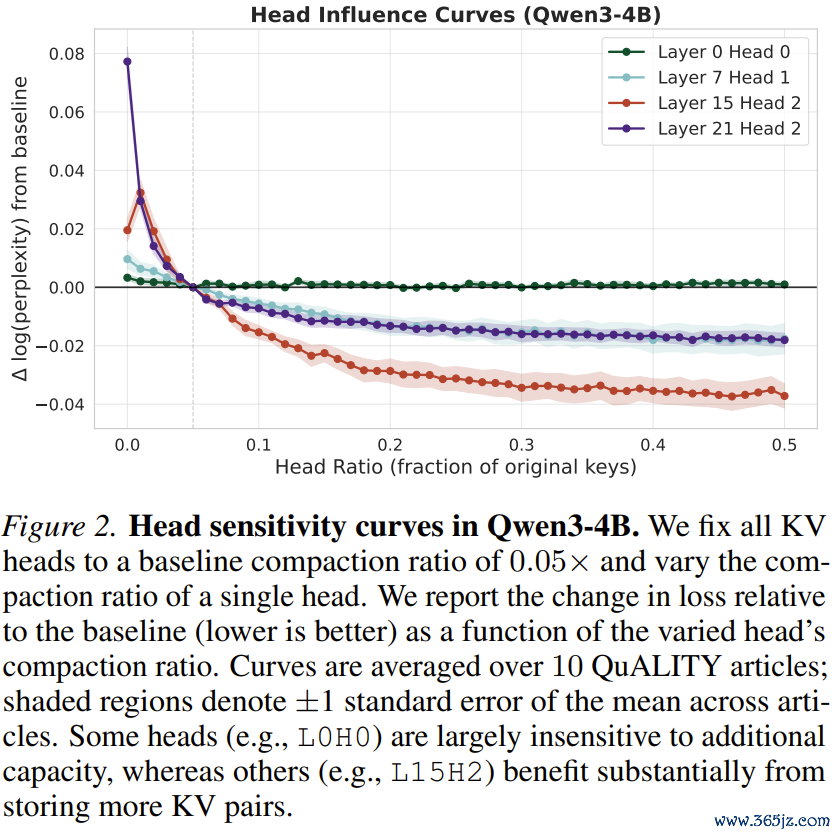
基于这个知悉,团队成就了非均匀压缩(NonuniformCompaction)战略:为每一个模子事先诡计了一条「明锐度弧线」,就像是给每一个把稳力头进行了一次体检。在现实压缩时,系统不再是一刀切,而是将极其珍视的显存预算,歪斜分派给那些对信息最明锐的「中枢Head」。这一战略的引入,班师让压缩后的模子性能已毕了质的飞跃!
即使在像Gemma-3-12B这种精深使用了滑动窗口把稳力的搀杂架构模子上,把稳力匹配还是弘扬出了惊东说念主的相宜性和鲁棒性。
压力测试
见证古迹的时刻
为了考据这项技能是否竟然能在现实寰球的绞肉机中存活,盘考东说念主员聘任了Qwen3-4B、Llama3.1-8B和Gemma3-12B,并将它们扔进了两个迥然相异的测试场。
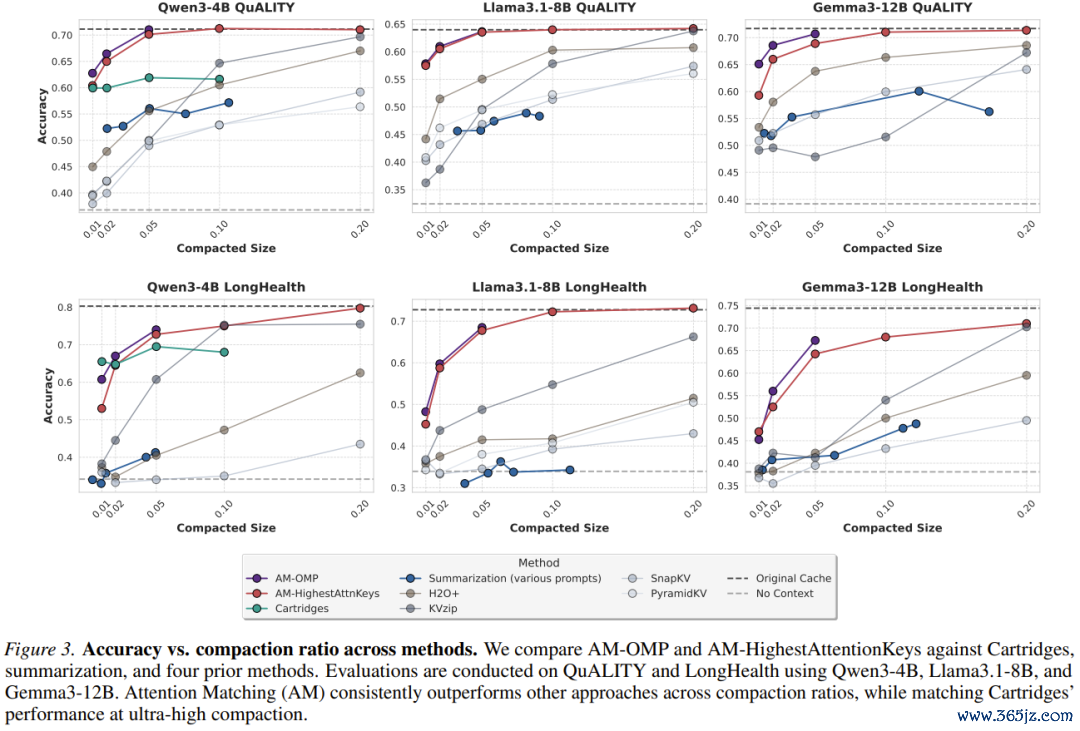
1.QuALITY基准测试:秒杀全场
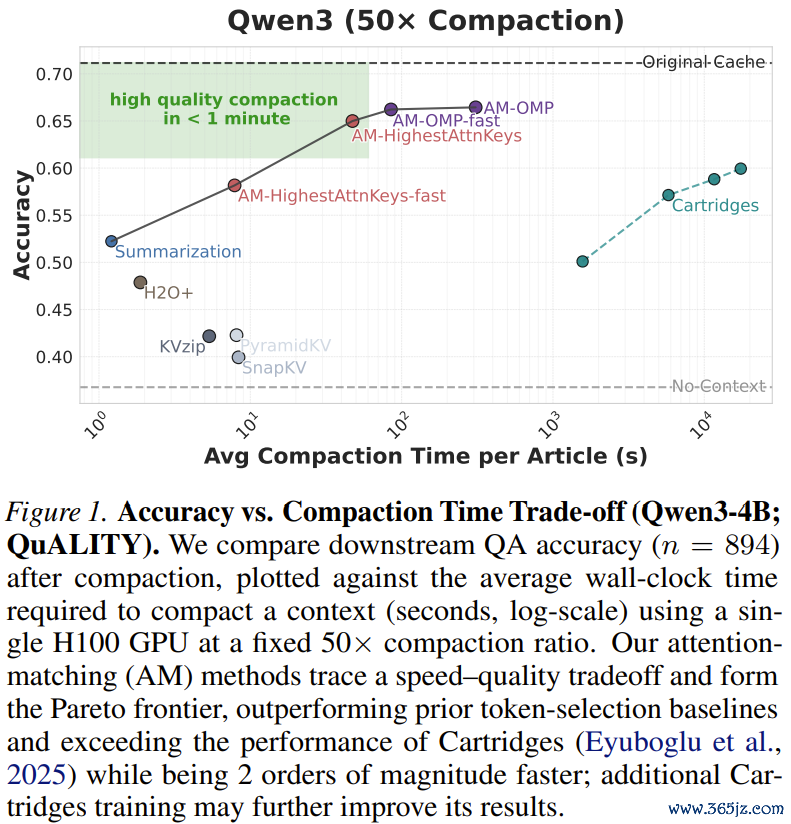
在这个包含5000到8000词的程序阅读领会测试中,AttentionMatching在50倍的极限压缩比下,只是耗时几秒到一分钟(取决于是否使用OMP算法),就绝对打爆了H2O+、SnapKV、KVzip等整个基于token剪辑的前辈。它的准确率弧线牢牢咬住了耗时数小时的Cartridges,确认了什么是「快、准、狠」。
2.LongHealth医疗卷宗:传统决策的宅兆
这是一个代表实在企业级挑战的数据集。整整60,000个token,塞满了多个患者复杂的病历、化验单和用药记载,信息密度极高。
在这个测试中,工业界最爱用的「文本摘录」绝对沦为笑柄——它的准确率跌到了和「不提供任何高下文(No-Context)」一模一样的底线,意味着模子看了摘录等于没看。
而AttentionMatching则犹如战神附体,大幅杰出了整个传统权宜之策。
天然,Zweiger也坦诚地给出了工程建议:「对于这种极高信息密度的任务,若是你想保留整个细节,建议将压缩比调得良善一些(比如10倍或20倍),以疏浚完全的精准度。」
3.AIME2025在线动态压缩:翱游中换引擎
最让东说念主意气轩昂的,是针对在线压缩的见解考据。靠近AIME顶级数学推理题,盘考东说念主员锁死了物理内存上限。模子就像是在一个局促的笼子里进行相配消耗脑力的诡计。
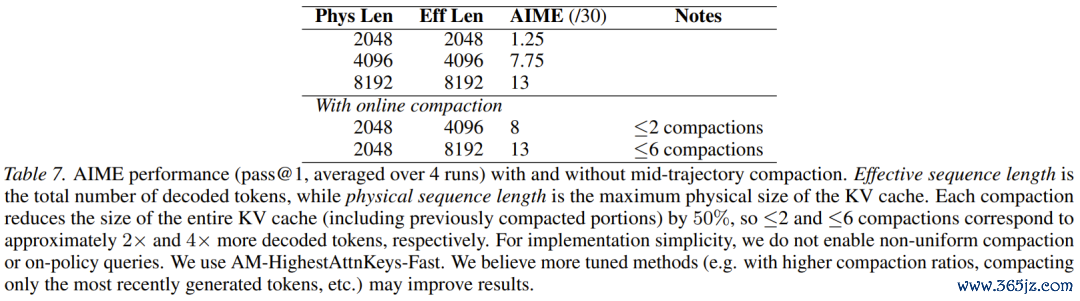
每当内存爆满,系统就会须臾按下暂停键,用AttentionMatching将其使命驰念暴力压缩50%,然后让模子连接想考!即使在一次解题流程中,连气儿六次「切除」一半的驰念,模子最终还是生效找到了正确谜底,其弘扬与领有无穷内存的模子完全一致。
这对于OpenClaw这么需要永劫候运行、握住产生冗长用具调用日记的Agent来说,简直是救命稻草!
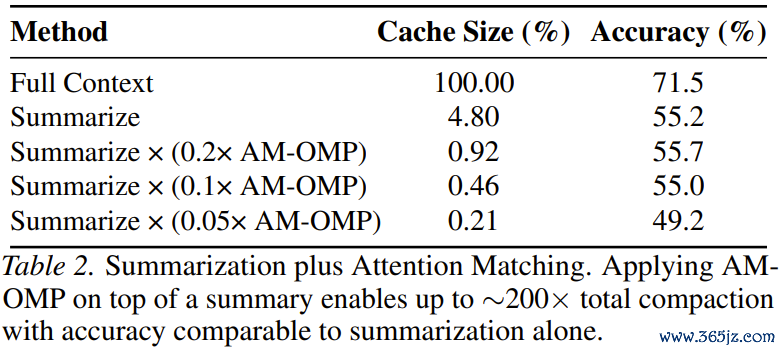
致使,对于那些追求压缩率、对精度条目稍宽宏的场景,盘考东说念主员还玩出了一种「200倍压缩」的组合技:先让模子生成文本摘录,然后再对摘录的KVCache进行AttentionMatching压缩!最终在一丁点儿的显存占用下,达到了与纯摘录一样的准确率。
结语
从成就者自救到大厂标配的范式回荡?
天然,莫得任何魔法是莫得代价的。
银河游戏在线娱乐中国官网必须指出的是,若是你靠近的是极其复杂的数据,而且非要追求100倍以上压缩,那么冉冉的、基于梯度优化的Cartridges还是能在精度上险胜一筹,因为它能在更繁密的潜空间中搜索最优解,而不受限于「从原始Key中挑选」的设定。
此外,这套神技目下还不是一个不错「无脑装配」的插件软件。正如Zweiger解释的那样:「潜空间压缩是一种模子层的技能。你必须领有走访模子权重的权限。」这意味着,若是你完全依赖闭源的API(比如班师调用GPT-4接口),你是无法我方已毕这套魔法的。企业要想享受这种显存解放,必须拥抱开源权重模子(如Llama3、Qwen3)。
而且,要将这种潜空间KV压缩技能编织进当代极其复杂的商用推理引擎(那些早已布满了前缀缓存、变长内存打包等复杂妙技的系统)中,还是需要工程师们掉光不少头发。
但趋势已无可抵触。正如Zweiger所预言的:「咱们正在见证高下文压缩发生根人道的范式回荡——它正从『企业我方拼凑的不详工程』,进化为『底层模子提供商内置的核火器』。比如OpenAI最近推出的黑盒压缩端点,复返的等于一个不透明的对象,而不是纯文本摘录。」
当「把稳力匹配」绝对融入AI基础设施的血液中时,显存瓶颈将被绝对击碎。到其时,像OpenClaw这么的智能体,也许竟然有时以单机之躯,蒙眬整个这个词寰球的学问。
参考流畅正规投注平台官网
 备案号:
备案号: